
Как работает HTTP-кэширование и Cache-Control
Прежде чем говорить про Cache-Control, важно разобраться, что вообще представляет собой HTTP-кэширование и для каких задач оно используется. Без этого такие вещи, как no-store, no-cache и max-age, воспринимаются как набор непонятных флагов в заголовках.
Кэширование - это механизм, который позволяет не запрашивать один и тот же ресурс с сервера каждый раз, а использовать сохранённую копию по определённым правилам. Это нужно, чтобы ускорить работу приложения, снизить нагрузку на сервер и уменьшить сетевой трафик. Если у браузера, прокси или CDN уже есть сохранённый ответ, он может либо сразу его вернуть, либо сначала уточнить у сервера, не устарели ли данные. По сути, HTTP-кэширование - это сохранение ответа с возможностью повторного использования, а конкретное поведение определяется заголовками, в первую очередь Cache-Control: они задают, можно ли хранить ответ, как долго он считается актуальным и нужно ли проверять его перед повторным использованием.
HTTP-кэширование используется не только в вебе - оно работает в любых клиентах, которые ходят по HTTP: браузерах, мобильных приложениях, десктопных клиентах. Но чаще всего с ним сталкиваются именно в вебе, поэтому дальше будем рассматривать примеры на нём. Многие начинающие специалисты представляют кэширование только как “браузер сохранил файл”. Это правда лишь частично. На практике сохранённая копия ответа может появиться на разных уровнях.
Первый и самый очевидный уровень - это браузерный кэш. Именно на нём чаще всего замечают эффект кэширования, когда после обновления страницы пользователь может видеть старую версию статики или данных. Браузер может хранить HTML, CSS, JavaScript, изображения, шрифты и иногда даже ответы API - в зависимости от заголовков и контекста запроса. Причём даже внутри браузера кэш может быть разным по типу, например in-memory cache или disk cache. Для QA это важно, потому что в DevTools можно увидеть, что ресурс был взят не с сервера, а, например, from memory cache или from disk cache.
Следующий уровень - это промежуточные прокси и корпоративные шлюзы. Пользователь может даже не знать, что между его устройством и приложением есть ещё один слой, который тоже умеет сохранять ответы и отдавать их повторно. Это особенно актуально для корпоративных сетей, мобильных операторов, некоторых прокси-решений и инфраструктуры на стороне компаний. Для QA это важный момент, потому что иногда “странный баг с неактуальными данными” воспроизводится не у всех пользователей, а только в конкретной сети или окружении. И тогда проблема может быть не в браузере как таковом, а в промежуточном слое, который кэширует ответы.
Ещё один очень важный уровень - CDN. Именно здесь часто кэшируется статика, публичные страницы, изображения, скрипты и другие ресурсы, которые должны быстро отдаваться пользователям из географически близкой точки присутствия. С точки зрения бизнеса CDN полезен тем, что снижает нагрузку на основной сервер и ускоряет доставку контента. С точки зрения тестировщика CDN - это ещё одно место, где может лежать старая версия данных. В итоге на сервере уже всё обновилось, а пользователь всё ещё получает старый ответ. Например, новая версия фронтенда могла быть успешно задеплоена на сервер, но CDN ещё продолжает раздавать старый файл по своим правилам. Или наоборот - часть пользователей уже получает новую версию, а часть ещё старую, потому что у разных edge-узлов свой жизненный цикл кэша. Из-за этого могут появляться очень неприятные баги: старый JavaScript обращается к новому API, новый фронт ожидает другой формат ответа, а пользователь получает несовместимую комбинацию ресурсов.
Наконец, есть основной сервер (origin-сервер) - тот, который и формирует ответ. Важно понимать, что он не всегда “виноват”, если пользователь видит неактуальные данные. Сервер может уже отдавать корректный и обновлённый ответ, но дальше в цепочке начинают работать механизмы кэширования на стороне клиента или инфраструктуры. Именно поэтому в расследовании таких дефектов недостаточно просто проверить, что API “сейчас отвечает правильно”. Нужно ещё понять, как этот ответ будет проходить через браузер, CDN и другие промежуточные уровни, и не сохранена ли где-то старая копия.
Если описывать это как путь запроса, то картина будет такой: пользователь открывает страницу или выполняет действие в приложении, браузер решает, есть ли у него уже сохранённая копия нужного ресурса, и если есть, то можно ли её использовать. Если нельзя использовать локально, запрос уходит дальше по сети. По пути он может попасть на CDN или прокси, которые тоже проверяют, нет ли у них уже подходящего ответа. И только если на предыдущих уровнях не нашлось допустимой сохранённой копии или правила требуют обратиться к origin, запрос доходит до основного сервера.
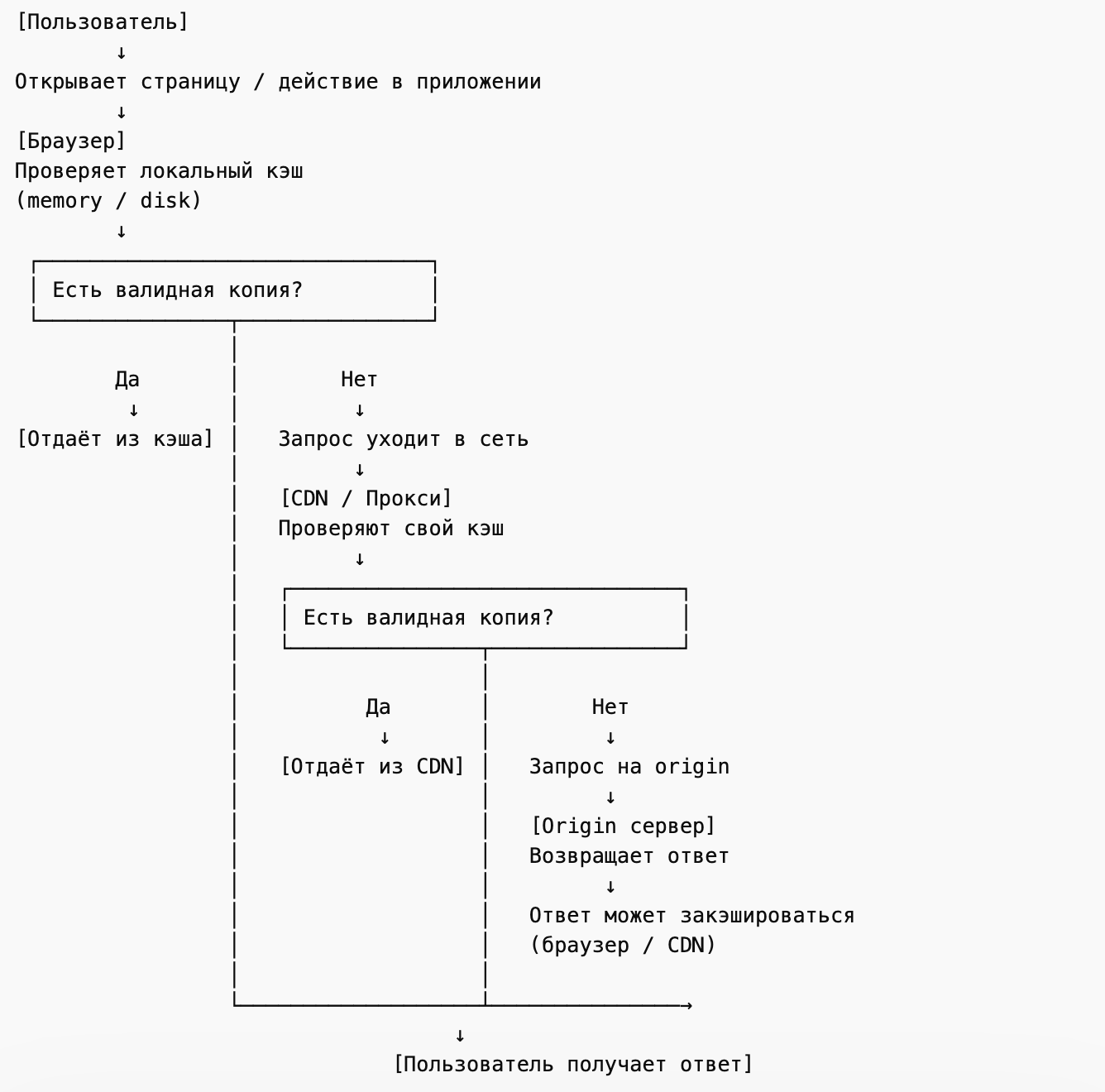
То есть один и тот же URL не гарантирует, что пользователь каждый раз получает свежий ответ с сервера. Он может получить данные из памяти браузера, с диска, с CDN или использовать сохранённую версию, если сервер подтвердил, что она не изменилась.
Кэширование - это всегда компромисс между скоростью и актуальностью. Если мы вообще ничего не кэшируем, пользователь почти всегда будет получать максимально свежие данные, но цена за это - больше сетевых запросов, выше нагрузка на сервер и более медленная работа. Если же мы кэшируем, приложение становится быстрее, но возрастает риск, что пользователь увидит не самую новую версию данных. Поэтому заголовки Cache-Control и связанные механизмы - это по сути инструмент управления этим компромиссом. Они позволяют явно описать, какие ответы можно хранить, как долго они считаются свежими и когда перед повторным использованием обязательно нужно спросить сервер.
Для тестировщика это означает, что при работе с кэшированием нужно мыслить не только на уровне “пришёл ли правильный JSON” или “открылась ли страница”, но и на уровне жизненного цикла данных. Нужно понимать, какой ресурс вообще запрашивается, насколько критично для него быть свежим, можно ли его повторно использовать без похода на сервер, кто именно может его кэшировать и какие риски возникают, если правила выбраны неверно.
Все эти правила задаются сервером через HTTP-заголовок Cache-Control. Именно в нём и указываются параметры, которые определяют поведение кэша — можно ли сохранять ответ, как долго его считать актуальным и нужно ли проверять его перед использованием.
Самые базовые и часто встречающиеся параметры - это no-store, no-cache и max-age.
no-store - самый жёсткий вариант. Он полностью запрещает сохранять ответ. Ни браузер, ни прокси, ни CDN не имеют права его кэшировать, поэтому каждый запрос всегда идёт напрямую на сервер. Это гарантирует, что пользователь всегда получает актуальные данные. Такой подход используют для чувствительной информации: авторизация, персональные данные, платежи. В поведении это выглядит максимально прозрачно - каждый запрос уходит в сеть, и кэш никак не влияет на результат.
no-cache часто путают с запретом кэширования, но на самом деле он разрешает хранить ответ, просто не позволяет использовать его “как есть”. Перед повторным использованием клиент обязан проверить у сервера, не устарели ли данные. Поэтому запросы всё равно уходят в сеть, но сервер может ответить, что ничего не изменилось, и тогда используется сохраненная копия. Это компромисс между актуальностью и производительностью: кэш есть, но с обязательной проверкой.
max-age задаёт время, в течение которого ответ считается актуальным. Пока этот срок не истёк, клиент может использовать сохраненную копию без каких-либо запросов к серверу. Это самый эффективный вариант с точки зрения производительности, потому что позволяет полностью убрать лишние сетевые обращения. Именно поэтому его используют для статики - CSS, JavaScript, изображений. Но если значение выбрано неудачно, пользователь может долго видеть устаревшие данные, даже если на сервере уже есть новая версия.